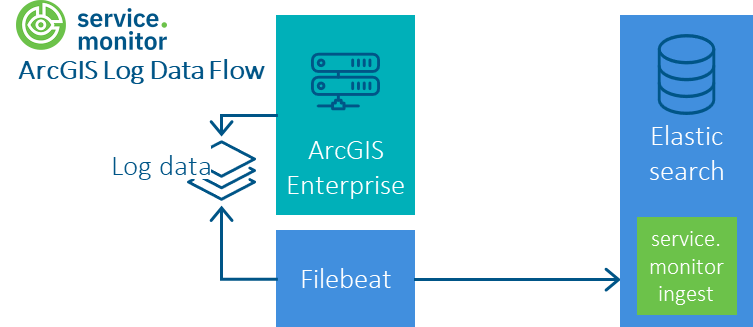
ArcGIS Enterprise log data
Procedure
Configuration of Filebeat with Elasticsearch as output
The delivery of service.monitor contains a Filebeat configuration in the directory \resources\analytics\elasticsearch\filebeat\arcgis-logfile, which
enables ArcGIS log files to be written to an Elasticsearch index using Filebeat. The data is transformed by a referenced ingest pipeline.
The configuration can be combined with other data sources, e.g. FME Flow. An example can be found in the directory \resources\analytics\elasticsearch\filebeat\arcgis-fme-logfile.