ArcGIS Enterprise log data
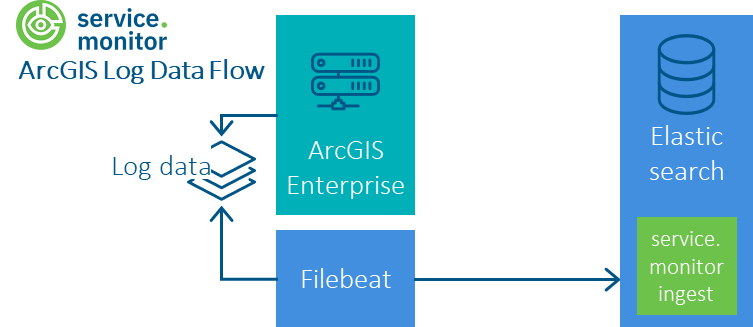
Procedure
-
Configuring Filebeat on the ArcGIS Enterprise Host to poll the log files on a regular basis (see below)
-
Verify ArcGIS Log Level is set correctly (see below)
Configuration of Filebeat without Logstash
FME log files can be written by Filebeat to a logstash or ingest pipeline. To dispense with the Logstash installation, an elasticsearch index with an ingest pipeline can also be used directly with the following configuration.
arcgis.env: 'production'
# arcgis.base.path: 'c:\arcgisserver\logs'
arcgis.base.path: ''
filebeat.inputs:
- type: filestream
id: "arcgis_logfiles-server"
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched for ArcGIS Enterprise logs. Glob based paths.
# Adopt these paths/patterns according to your environment
paths:
- ${arcgis.base.path}\*\server\*.log
- ${arcgis.base.path}\*\services\*\*.log
- ${arcgis.base.path}\*\services\*\*\*.log
- ${arcgis.base.path}\*\services\System\*\*.log
fields_under_root: true
fields:
labels:
env: ${arcgis.env}
source: 'arcgis-server'
### Multiline options
# Match can be set to "after" or "before". It is used to define if lines should be append to a pattern
# that was (not) matched before or after or as long as a pattern is not matched based on negate.
#
# Note: This needs only be adopted if the ArcGIS Server Log files structure changes
multiline.pattern: '^<Msg([^>]*?)>(.*)'
multiline.negate: true
multiline.match: after
- type: filestream
id: "arcgis_logfiles-portal"
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched for ArcGIS Enterprise logs. Glob based paths.
# Adopt these paths/patterns according to your environment
paths:
- ${arcgis.base.path}\portal\*.log
fields_under_root: true
fields:
labels:
env: ${arcgis.env}
source: 'arcgis-portal'
### Multiline options
# Match can be set to "after" or "before". It is used to define if lines should be append to a pattern
# that was (not) matched before or after or as long as a pattern is not matched based on negate.
#
# Note: This needs only be adopted if the ArcGIS Server Log files structure changes
multiline.pattern: '^<Msg([^>]*?)>(.*)'
multiline.negate: true
multiline.match: after
- type: filestream
id: "arcgis_logfiles-datastore"
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched for ArcGIS Enterprise logs. Glob based paths.
# Adopt these paths/patterns according to your environment
paths:
- ${arcgis.base.path}\datastore\*.log
fields_under_root: true
fields:
labels:
env: ${arcgis.env}
source: 'arcgis-datastore'
### Multiline options
# Match can be set to "after" or "before". It is used to define if lines should be append to a pattern
# that was (not) matched before or after or as long as a pattern is not matched based on negate.
#
# Note: This needs only be adopted if the ArcGIS Server Log files structure changes
multiline.pattern: '^<Msg([^>]*?)>(.*)'
multiline.negate: true
multiline.match: after
[...]
# ======================= Elasticsearch template setting =======================
setup.ilm:
enabled: true # setting this to true will ignore setup.template.name, setup.template.pattern and output.elasticsearch index
policy_name: "ct-arcgis-logfile-policy"
overwrite: false
rollover_alias: "ct-arcgis-logfile"
pattern: "{now/d}-0000001"
# This section is ignored, when setup.ilm.enabled is true
# setup.template.name: "ct-arcgis-logfile"
# setup.template.pattern: "ct-arcgis-logfile-*"
# setup.template.settings:
# index.number_of_shards: 1
# ================================== Outputs ===================================
# --------------------------- Elasticsearch Output -----------------------------
output.elasticsearch:
# the index configuration is ignored when setup.ilm.enabled is true. In this case the setup.ilm.rollover_alias is used as target.
# index: "ct-arcgis-logfile-*"
# The name of the ingest pipeline processing the filebeat input.
pipeline: "ct-monitor-arcgis-logfile"
# Elasticsearch host and port
hosts: ["https://localhost:9200"]
# Elasticsearch user name
username: ""
# Elasticsearch password
password: ""
ssl:
enabled: true
# Elasticsearch SSL fingerprint
ca_trusted_fingerprint: ""
# ================================= Processors =================================
[...]Configuration of Filebeat without Logstash, in combination with FME log files
If, in addition to ArcGIS log files, FME log files are also to be read in with Filebeat, a filebeat.yml can be used for this purpose in the filebeat/arcgis-fme-logfile folder.
This combines the two pipelines.
Configuration of FileBeat with Logstash

The Filebeat configuration is then done on the basis of the template filebeat/arcgis-logfile/filebeat.yml.
###################### Filebeat Configuration Example #########################
# This file is an example configuration file for service.monitor analytics
# with regard to ArcGIS Server Log file harvesting. The fields in this file
# are the mandatory options that need to be set for filebeat to run. At a minimum,
# the following fields need to be adopted according to your environment:
# filebeat.inputs.paths: Where are my log files that shall be harvested by filebeat?
# filebeat.inputs.fields: What is my ArcGIS Server environment?
# output.logstash.hosts: What is the hostname and port of my logstash server(s)?
# # # #
# You can find the full configuration reference for filebeat.yml here:
# https://www.elastic.co/guide/en/beats/filebeat/index.html
# For more available modules and options, please see the filebeat.reference.yml sample
# configuration file.
# ============================== Filebeat inputs ===============================
# The value of this option will be added to the "labels.env" field in the index.
arcgis.env: 'production'
# arcgis.base.path: 'c:\arcgisserver\logs'
arcgis.base.path: ''
filebeat.inputs:
- type: filestream
id: "arcgis_logfiles-server"
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched for ArcGIS Enterprise logs. Glob based paths.
# Adopt these paths/patterns according to your environment
paths:
- ${arcgis.base.path}\*\server\*.log
- ${arcgis.base.path}\*\services\*\*.log
- ${arcgis.base.path}\*\services\*\*\*.log
- ${arcgis.base.path}\*\services\System\*\*.log
fields_under_root: true
fields:
labels:
env: ${arcgis.env}
source: 'arcgis-server'
### Multiline options
# Note: This needs only be adopted if the ArcGIS Server Log files structure changes
parsers:
- multiline:
type: "pattern"
pattern: '^<Msg([^>]*?)>(.*)'
negate: true
match: "after"
skip_newline: false
- type: filestream
id: "arcgis_logfiles-portal"
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched for ArcGIS Enterprise logs. Glob based paths.
# Adopt these paths/patterns according to your environment
paths:
- ${arcgis.base.path}\portal\*.log
fields_under_root: true
fields:
labels:
env: ${arcgis.env}
source: 'arcgis-portal'
### Multiline options
# Note: This needs only be adopted if the ArcGIS Server Log files structure changes
parsers:
- multiline:
type: "pattern"
pattern: '^<Msg([^>]*?)>(.*)'
negate: true
match: "after"
skip_newline: false
- type: filestream
id: "arcgis_logfiles-datastore"
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched for ArcGIS Enterprise logs. Glob based paths.
# Adopt these paths/patterns according to your environment
paths:
- ${arcgis.base.path}\datastore\*.log
fields_under_root: true
fields:
labels:
env: ${arcgis.env}
source: 'arcgis-datastore'
### Multiline options
# Note: This needs only be adopted if the ArcGIS Server Log files structure changes
parsers:
- multiline:
type: "pattern"
pattern: '^<Msg([^>]*?)>(.*)'
negate: true
match: "after"
skip_newline: false
# ============================== Filebeat modules ==============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# Period on which files under path should be checked for changes
reload.period: 10s
# ======================= Elasticsearch template setting =======================
# we handle ilm and templates in elasticsearch
setup.ilm.enabled: false
setup.template.enabled: false
# ================================== Outputs ===================================
# --------------------------- Elasticsearch Output -----------------------------
output.elasticsearch:
# index can be defined as index pattern, when ilm is activated in elasticsearch.
index: "ct-arcgis-logfile"
# The name of the ingest pipeline processing the filebeat input.
pipeline: "ct-monitor-arcgis-logfile"
# Elasticsearch host and port
hosts: ["https://localhost:9200"]
# Elasticsearch username
username: ""
# Elasticsearch password
password: ""
ssl:
enabled: true
# Elasticsearch SSL fingerprint
ca_trusted_fingerprint: ""
# ================================= Processors =================================
# The following section needs no adoptions
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
Select the value under arcgis.source from arcgis-server, arcgis-portal, arcgis-datastore to get better filtering possibilities in Kibana. The same applies to arcgis.env to distinguish between different stages.
|