Elastic Data Ingesting
Introduction
With ingesting pipelines, you can modify and extend incoming events or events already present on the server. They are comparable to Logstash pipelines, but do not have the same functionality. However, because they are executed in the Elasticsearch process, ingest pipelines are much easier to use.
In the context of service.monitor, there are currently the following pipelines:
-
Calculation of extended time and date values
-
Detailed examination of ArcGIS log data
-
Extract ArcGIS service information from Monitoring events
The pipeline files are located in the delivery under elasticsearch/ingest.
|
Use Cases
Temporal Adjustments
The pipeline ct-monitor-temporal allows the calculation of the following additional time values:
-
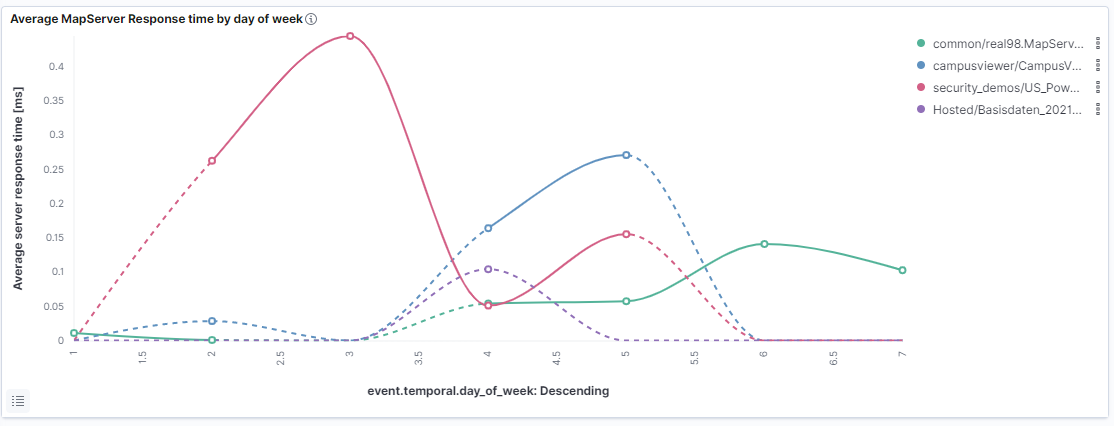
day of week
-
name of day of week
-
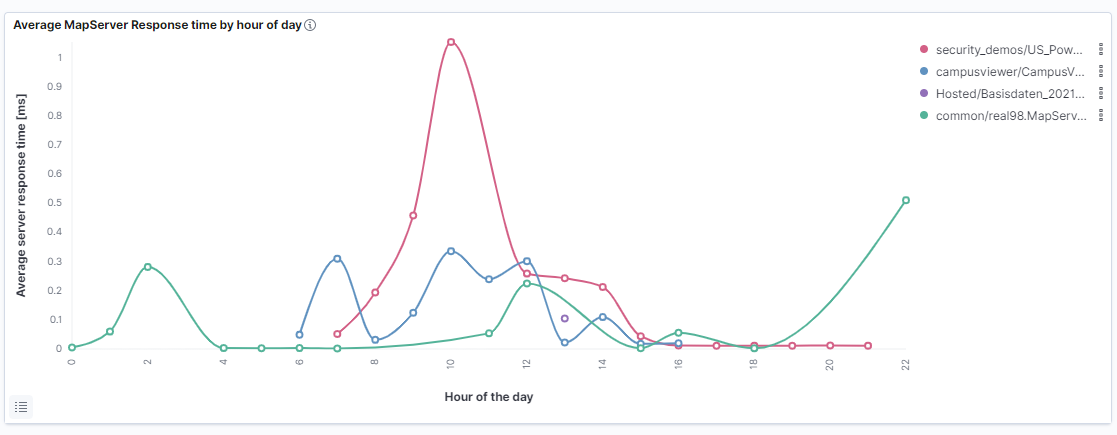
hour of day
-
day of year
-
number of month
This can be used to create diagrams that, for example, visualise or aggregate measured values on a daily or weekly basis.
| By calculating these values, a defined time zone is used (here: 'Europe/Paris'), this must be adjusted if necessary. |
In-depth ArcGIS analysis
The pipeline ct-monitor-arcgis-parse-servicename allows the extraction of service information from ArcGIS Server messages.
In most cases the service concerned is stored in a separate attribute of the ArcGIS message, but in some cases it is only present in the message text of the log line.
The pipeline is able to recognise service names via Grok patterns and transfer them into the standard field of the event.
|
This pipeline helps to find service timeouts, for example. Error performing query operation Error handling service request :Processing request took longer than the usage timeout for service |
ArcGIS service information extraction
The ct-monitor-arcgis-serviceinfo pipeline makes it possible to extract ArcGIS service information from Monitoring events.
ct-monitor-arcgis-serviceinfo pipeline[...]
"service" : {
[...]
"host" : "services.conterra.de",
"ags": {
"url-path" : "/arcgis/rest/services/mapapps/stoerung_relates/MapServer",
"arcgis-service-name" : "mapapps",
"arcgis-folder" : "stoerung_relates",
"arcgis-service-and-folder" : "mapapps/stoerung_relates"
},
[...]
}Usage
Running pipelines for inventory data
POST _reindex
{
"source": {
"index": "source_index"
},
"dest": {
"index": "target_index",
"pipeline": "pipeline-name"
}
}The _update_by_query feature can also be used to update old data.
In the example below, a query is used to apply the pipeline only to certain events.
POST <index>/_update_by_query?pipeline=pipeline-name
{
"query": {
"match": {
"_id": "9_BGMnoBoGFrpZgJVWVE"
}
}
}Execute pipelines for all incoming events
You can set a pipeline as default in the pipeline settings .
| Set the same value on the associated index template to enable the pipeline on all subsequent indexes as well. |