FME Flow
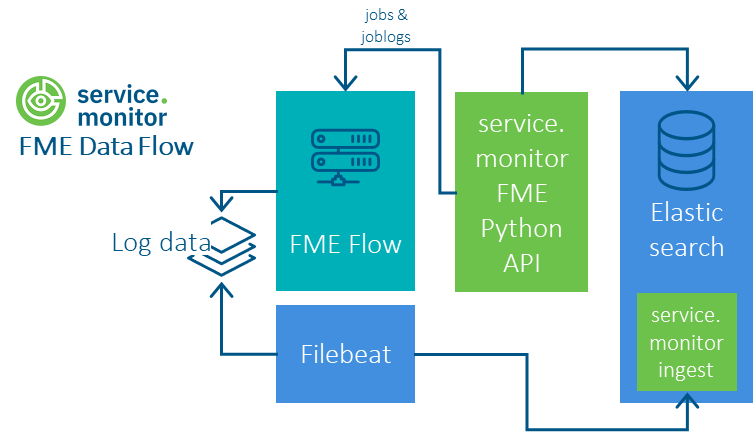
Ablauf
-
FME Flow Token generieren
-
Einrichtung der Python-FME-Jobs
-
Einrichtung von Filebeat für Server-only-Dateien
FME Flow Token generieren
Es ist sinnvoll, in FME Flow einen eigenen Nutzer-Account explizit für die Verbindung mit service.monitor zu erstellen und für diese Nutzer ein FME Token zu generieren. Folgende Rechte werden für den Zugriff auf FME bei der Token-Generierung in FME benötigt:
| Permission | Level |
|---|---|
Jobs |
Manage |
Queue Control |
Manage |
Einrichtung der Python-FME-Jobs
An die Stelle der Logstash-Pipelines aus den Vorversionen ist eine Python-API getreten, die einen performanten, verlässlichen und leicht konfigurierbaren Einsatz ermöglicht. Über diesen Weg können die FME Flow Jobs, die FME Job Logs und die FME Queues abgefragt werden.
Voraussetzung für die Nutzung ist eine Python-3-Umgebung und die Installation von pipelines-1.0.0-py3-none-any.whl. Siehe dazu README.md im Ordner resources/analytics/python/pipelines.
Danach sollten folgende Schritte erfolgen:
-
Konfigurationsdatei config.json anlegen
-
Skript auf der Kommandozeile testen
-
Skript in ausführbare Datei einbetten
-
kontinuierliche Ausführung konfigurieren
{
"elasticsearch": {
"url": "http://elastic.host.company.com:9200",
"username": "elastic",
"password": "<elastic_pwd>",
"job_index": "ct-fme-jobs",
"log_index": "ct-fme-log",
"job_route_index": "ct-fme-jobroutes"
},
"fme": {
"token": "<token>",
"url": "http://fme.host.company.com",
"pagesize": 1000,
"stage": "test"
},
"pipeline": {
"job_logs": {
"enabled": true,
"batch_size": 20
}
}
}elasticsearch/url |
URL zur Elastic-Instanz |
|---|---|
elasticsearch/user |
Name des Nutzers |
elasticsearch/password |
Passwort des Nutzers |
fme/url |
URL zu FME Flow |
fme/token |
FME Flow Token |
fme/stage |
Label, um die Ereignisse gemäß ihrer Stage zu kennzeichnen |
python -m pipelines.fmejob -c /opt/conterra/fme/config.json#!/bin/sh
python -m pipelines.fmejob -c /opt/conterra/fme/config.json*/10 * * * * /home/monitor/fme-python/job-run.shKonfiguration von Filebeat (Server seitige Logdaten)
Für jeden FME Host, der am Sammeln der Log-Daten beteiligt sein soll, muss die Komponente Filebeat installiert werden. Aktuell wird Filebeat 7.x unterstützt, mit Filebeat 8.x konnten noch keine Probleme festgestellt werden.
Die Filebeat-Konfiguration erfolgt danach auf Basis der Vorlage filebeat/fme-logfile/filebeat.yml.
# fme.base.path: '/var/log/fme'
fme.base.path: ''
# The value of this option will be added to the "labels.env" field in the index.
fme.env: 'production'
filebeat.inputs:
- type: "filestream"
id: "fme_server_core"
enabled: true
fields_under_root: true
fields:
labels:
env: ${fme.env}
source: "fme_server_core"
pipeline: "ct-monitor-fme-log"
paths:
- "${fme.base.path}/logs/core/current/*.log"
parsers:
- multiline:
type: "pattern"
pattern: '^(\w{3}-\d{2}-\w{3}-\d{4} \d{2}:\d{2}:\d{2}.\d{3})\s((AM|PM)+)'
negate: true
match: "after"
skip_newline: true
[... more inputs ...]
# ======================= Elasticsearch template setting =======================
setup.template.name: "ct-fme-log"
setup.template.pattern: "ct-fme-log-*"
setup.ilm:
enabled: true
policy_name: "ct-fme-log-policy"
overwrite: false
rollover_alias: "ct-fme-log"
pattern: "{now/d}-0000001"
# ================================== Outputs ===================================
# --------------------------- Elasticsearch Output -----------------------------
output.elasticsearch:
# The name of the target index
index: "ct-fme-log-*"
# The name of the ingest pipeline processing the filebeat input.
pipeline: "ct-monitor-fme-log"
# Elasticsearch host and port
hosts: ["https://localhost:9200"]
# Elasticsearch user name
username: ""
# Elasticsearch password
password: ""
ssl:
enabled: true
# Elasticsearch SSL fingerprint
ca_trusted_fingerprint: ""
Über die Variable fme.base.path kann das Basisverzeichnis der Logdaten auf dem FME Host einmalig für alle Inputs definiert werden.
|
Über die Variable fme.env kann die Umgebung, die eingebunden wird, hinsichtlich ihrer Stage beschrieben werden: z.B. production oder test.
|
Einrichtung der Logstash Pipelines (deprecated, nicht verpflichtend)
Falls sämtliche logstash-Pipeline-Ordner des service.monitor bereits in Logstash vorliegen, müssen die drei FME-Pipelines über die Datei pipelines.yml "aktiviert" werden.
Pipeline konfigurieren
Die FME-Pipelines müssen über das Setzen von Variablen konfiguriert werden, bevor sie erfolgreich in Betrieb genommen werden können.
| Variable | Default | Erklärung |
|---|---|---|
FME_SERVER_BASE_URL |
<leer> |
URL des Hosts auf dem FME läuft, inkl. Protokoll, z.B.: |
FME_SERVER_TOKEN |
<leer> |
FME Flow Token zur Authentifizierung des Requests bei FME |
FME_SERVER_LIMIT |
1000 |
Anzahl der Jobs, die pro Request bei FME Flow abgefragt werden sollen |
FME_SERVER_SCHEDULE |
6h |
Polling-Intervall für FME-Server Jobs |
ES_HOST |
localhost |
Angabe der Adresse von Elasticsearch, z.B. |
ES_USER |
<leer> |
Nutzername für die Authentifizierung bei Elasticsearch |
ES_PASSWORD |
<leer> |
Passwort für die Authentifizierung bei Elasticsearch |
Die Verwendung der ct-fme-*-Logstash-Pipelines wird nicht mehr empfohlen.
