FME Flow
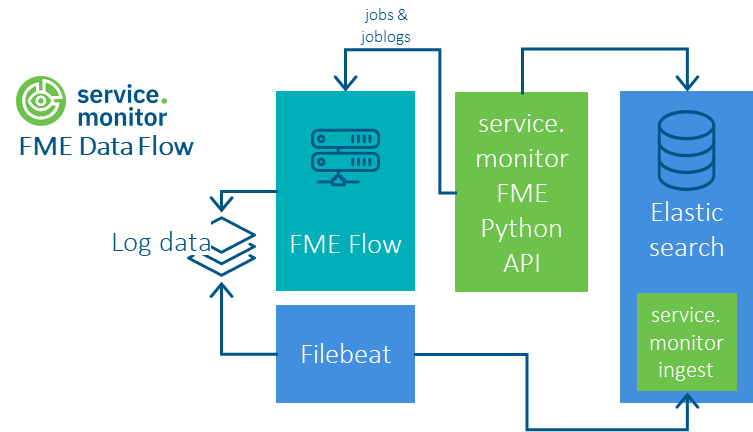
Ablauf
-
FME Flow Token generieren
-
Einrichtung der Python-FME-Jobs
-
Einrichtung von Filebeat für Server-only-Dateien
FME Flow Token generieren
Es ist sinnvoll, in FME Flow ein eigenes Benutzerkonto explizit für die Verbindung mit service.monitor zu erstellen und für diesen Benutzer ein FME-Token zu generieren. Folgende Rechte werden für den Zugriff auf FME bei der Token-Generierung in FME benötigt:
| Permission | Level |
|---|---|
Jobs |
Manage |
Licensing & Engines |
Manage |
Queue Control |
Manage |
Einrichtung der Python-FME-Jobs
Über die Python-API können die FME Flow Jobs, die FME Job Logs und die FME Queues abgefragt werden.
Voraussetzung für die Nutzung ist eine Python-3-Umgebung und die Installation von pipelines-<version>-py3-none-any.whl. Siehe dazu README.md im Ordner resources/analytics/python/pipelines.
Danach sollten folgende Schritte erfolgen:
-
Konfigurationsdatei
config.jsonanlegen oder Optionen als System-Umgebungsvariablen setzen -
Skript auf der Kommandozeile testen
-
Skript in ausführbare Datei einbetten
-
kontinuierliche Ausführung konfigurieren
Folgende JSON-Struktur zeigt die Konfigurationsmöglichkeiten für den FME Python Client.
Alternativ können die Werte auch als System-Umgebungsvariablen gesetzt werden. Die Namen der Variablen folgen einem
Schema, das sich aus dem Pfad der JSON-Struktur ableitet, z.B. ELASTICSEARCH_URL.
{
"elasticsearch": {
"url": "http://elastic.host.example.com:9200",
"username": "elastic",
"password": "<elastic_pwd>",
"job_index": "ct-fme-jobs",
"log_index": "ct-fme-log",
"job_route_index": "ct-fme-queues",
"hash_username": true,
"username_hash_salt": ""
},
"fme": {
"token": "<token>",
"url": "http://fme.host.example.com",
"pagesize": 1000,
"stage": "test"
},
"pipeline": {
"job_logs": {
"enabled": true,
"batch_size": 20
},
"common": {
"verify_ssl_certs": false
},
"proxy": {
"url": "http://proxy-host.example.com",
"use_forwarding_for_https": false
}
}
}
|
URL zur Elastic-Instanz |
ELASTICSEARCH_URL |
|---|---|---|
|
Name des Nutzers |
ELASTICSEARCH_USER |
|
Passwort des Nutzers |
ELASTICSEARCH_PASSWORD |
|
Aktivierung der Hash-Funktion für den Nutzernamen |
ELASTICSEARCH_HASH_USERNAME |
|
Wert der in den Hash des Nutzernamens einfließt |
ELASTICSEARCH_USERNAME_HASH_SALT |
|
URL zu FME Flow |
FME_URL |
|
FME Flow Token |
FME_TOKEN |
|
Label, um die Ereignisse gemäß ihrer Stage zu kennzeichnen |
FME_STAGE |
|
Aktivierung der SSL-Zertifikatsprüfung |
COMMON_VERIFY_SSL_CERT |
|
Sobald eine Proxy-URL angegeben ist, wird der gesamte Datenverkehr über den Proxy geleitet. |
PROXY_URL |
|
Entscheidung ob Anfragen an den HTTPS-Proxy weitergeleitet oder ein TLS-Tunnel mithilfe der HTTP-CONNECT-Methode erstellt werden soll. In Standardszenarien muss diese Option nicht verändert werden. Das Forwarding kann beispielsweise genutzt werden, falls der genutzte Proxy die HTTP-CONNECT-Methode nicht unterstützt. |
PROXY_USE_FORWARDING_FOR_HTTPS |
python -m pipelines.fmejob -c /opt/conterra/fme/config.json#!/bin/sh
python -m pipelines.fmejob -c /opt/conterra/fme/config.json*/10 * * * * /home/monitor/fme-python/job-run.shKonfiguration von Filebeat (Serverseitige Logdaten)
Filebeat muss auf jeden FME Host installiert werden, für den Log-Dateien gesammelt werden sollen.
Die Auslieferung von $service.monitor enthält im Verzeichnis \resources\analytics\elasticsearch\filebeat\fme-logfile eine Filebeat Konfiguration, mit
der FME-Logdateien mittels Filebeat in einen Elasticsearch-Index geschrieben werden können. Die Daten werden durch eine referenzierte Ingest-Pipeline transformiert.
Die Konfiguration kann mit weiteren Datenquellen z.B. ArcGIS-Logs kombiniert werden. Ein Beispiel befindet sich im Verzeichnis \resources\analytics\elasticsearch\filebeat\arcgis-fme-logfile.
Über die Variable fme.base.path kann das Basisverzeichnis der Logdaten auf dem FME Host einmalig für alle Inputs definiert werden.
|
Über die Variable fme.env kann die Umgebung, die eingebunden wird, hinsichtlich ihrer Stage beschrieben werden: z.B. production oder test.
|