Job-Manager
Um bei der Suche Ergebnisse zu erzielen, müssen Sie zuerst einen Indexierungsjob anlegen. Dies wird über den Der Job-Manager durchgeführt. Dieser steht nach erfolgreicher Anmeldung eines Nutzers mit administrativen Rechten zur Verfügung (Standard-Nutzer: admin/admin).
Nach erfolgreicher Anmeldung können Sie den Job-Manager auf zwei Arten öffnen:
-
Über die Eingabe des Context
/smartfinder/managerin der Adresszeile des Browser, oder -
Durch Klick auf das Tool Job Manager in der Oberfläche.
Verwaltung von Indexierungsjobs
Nach erfolgreicher Anmeldung bzw. Aufruf sehen Sie folgende Oberfläche:
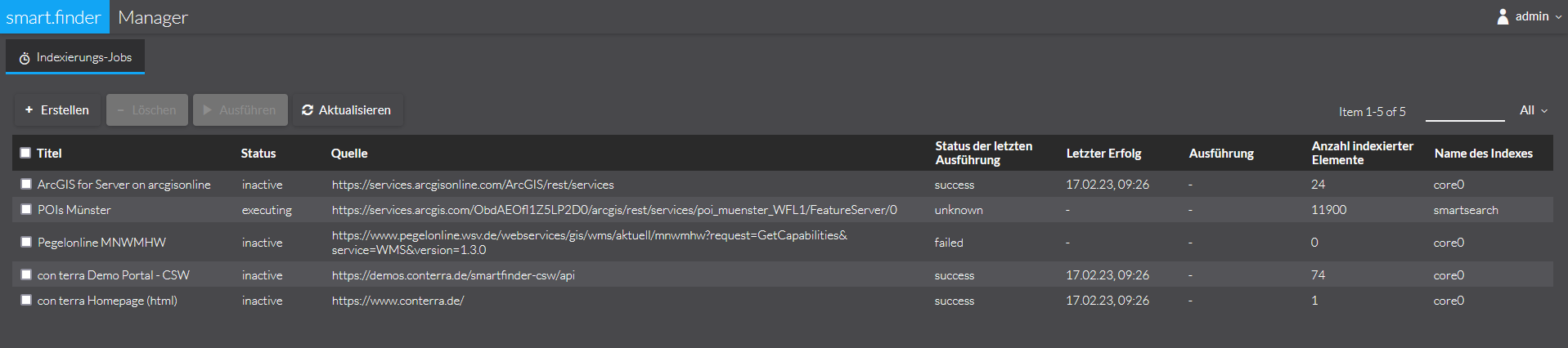
Hier sind alle publizierten Jobs gelistet. Diese sind wie folgt beschrieben:
| Parameter | Erläuterung |
|---|---|
Titel |
Der Titel des Jobs |
Status |
Der aktuelle Status der Indexierung. Folgende Status sind möglich:
|
Quelle |
Die Quelle, die durch diesen Job indexiert wird |
Status der letzten Ausführung |
successful oder failed |
Letzter Erfolg |
Datum der letzten erfolgreich durchgeführten Indexierung. |
Ausführung |
Ist ein Scheduling konfiguriert, so wird hier der nächste Ausführungszeitpunkt angezeigt. |
Anzahl indexierter Elemente |
Anzahl der Dokumente, die bei der letzten erfolgreich durchgeführten Indexierung in den Index aufgenommen worden sind. |
Name des Indexes |
Name des Index, in dem die Daten indexiert werden, siehe Cores und Indexes |
| Da die Indexierung der Jobs asynchron erfolgt wird die Anzahl der indexierten Dokumente für einen Job verzögert dargestellt. |
Anlegen von Indexierungs-Jobs
Klicken Sie zum Anlegen eines neuen Jobs auf das Plus-Symbol in der oberen linken Ecke. Es erscheint ein Auswahldialog, über den Sie die zu indexierende Quelle auswählen können.
Allgemeine Angaben
Jede Quelle benötigt eine Reihe von Parametern. Einige sind spezifisch, andere gelten allgemein für jede Quelle.
Die allgemeinen Parameter sind:
| Parameter | Erläuterung |
|---|---|
Titel |
Der Titel des Jobs |
Statusnachricht senden an |
Komma-separierte Liste von Email-Adressen, an die Statusänderungen geschickt werden |
Name des Index |
Der Name des Index, in den die Ressources der Quelle indexiert werden sollen. Wird kein Wert ausgewählt, so wird der Default-Index verwendet. Dieser wird durch das Property |
Scheduling |
Wiederholt die Ausführung des Jobs in festgelegten Intervallen. Siehe Indexierungs-Jobs zeitlich planen |
Die folgenden Abschnitte erläutern die spezifischen Parameter zu jeder Quelle.
Indexierungsquelle URL
Wählen Sie diesen Typ, wenn Sie Ressourcen indexieren möchten, die über eine URL adressierbar sind. Beispiele sind Ressourcen, die auf einer Web-Seite liegen oder auch GetCapabilities-Request.
| Parameter | Erläuterung |
|---|---|
URL |
URL der Quelle |
Filter |
Nur für Web-Site Crawling: regulärer Ausdruck, um die Weiterverfolgung von Links zu definieren. |
Suchtiefe |
Nur für Web-Site Crawling: Angabe der maximalen Suchtiefe innerhalb der Seiten-Hierarchie |
.pdf enden.URL: https://www.conterra.de/dir Filter: .*(\.(pdf))$ Suchtiefe: 2
Ergebnis:
https://www.conterra.de/dir/doc.pdf wird indexiert
https://www.conterra.de/dir/1/doc2.pdf wird indexiert
https://www.conterra.de/dir/1/doc3.xdoc wird nicht indexiert
https://www.conterra.de/dir/1/2/doc3.pdf wird nicht indexiert
Titel: WMS Demo Portal con terra URL: http://services.conterra.de/geoserver/wms?Request=GetCapabilities&Service=WMS
Ergebnis: Das Capabilities XML der URL wird indexiert.
Indexierungsquelle Dataimport Handler
Viele Anwendungen speichern ihre Inhalte in einem strukturierten Datenspeicher, wie z.B. einer relationalen Datenbank. Der Data Import Handler (DIH) ist ein Feature von Apache Solr und bietet einen Mechanismus zum Indizierung dieser Inhalten.
| Der smart.finder ermöglicht es, die Konfigurationsdatei eines Data Import Handlers einzulesen und im Job Manager einzubinden. Die Konfiguration für eine spezifische Datenquelle entnehmen Sie der Apache Solr Dokumentation . |
Data Import Handler Konfigurationen werden immer für einen spezifischen Index erstellt. Es gelten im smart.finder folgende Konventionen:
-
Diese Konfigurationsdateien müssen im
/confVerzeichnis des jeweiligen Index liegen. -
Der Name beginnt mit
dih-und endet mit.xml
Unter core0/conf/dih-sample.xml finden Sie die Beispielkonfiguration eines Data Import Handlers.
Dieses zeigt die Indexierung eines ATOM Feeds.
|
Um eine Konfigurationsdatei im Job-Manager einzubinden, wählen Sie die Option Datenimport. Folgende spezifische Parameter können angegeben werden:
| Parameter | Erläuterung |
|---|---|
Konfigurationsdatei |
Die |
Art des Imports |
|
| Ein Delta-Import kann nur mit einer Datenbank als Datenquelle durchgeführt werden. |
Indexierungsquelle OGC CSW Katalog
Um ISO Metadaten zu indexieren, die über eine OGC CSW 2.0.2 Schnittstelle zugreifbar sind, wählen Sie die Option OGC CSW Katalog. Geben Sie folgende Werte an:
| Parameter | Erläuterung |
|---|---|
URL |
HTTP POST Endpunkt der GetRecords-Schnittstelle des Katalogs |
Verteilte Kataloge indexieren |
Klicken Sie diese Option, falls Sie zusätzlich die ISO Metadaten indexieren wollen, die durch den o.g. Katalog im Rahmen einer verteilten Suche zugreifbar sind. |
Suchtiefe |
Nur relevant, wenn die Option verteilte Kataloge Indexieren aktiviert wurde und definiert die Suchtiefe für die verteilten Kataloge (der sogenannte |
OGC CSW KatalogWollen Sie z.B. den Katalog im Demo Portal der con terra indexieren, so geben Sie folgende Werte an:
Titel: CSW Demo Portal con terra URL: http://services.conterra.de/soapServices/CSWStartup Verteilte Kataloge indexieren: Ja Suchtiefe: 2
Der so definierte Job indexiert den CSW Katalog sowie alle angeschlossenen Katalog bis zu einer Suchtiefe von 2.
Indexierungsquelle Verzeichnis
Um Ressourcen zu indexieren, die in einem lokalen Verzeichnis vorliegen, wählen Sie die Option Verzeichnis. Geben Sie folgende Werte an:
| Parameter | Erläuterung |
|---|---|
Verzeichnis |
Das Basis-Verzeichnis, welches durchsucht werden soll. |
Verzeichnistiefe |
|
Dateitypen |
Ein optionaler Filter zur Einschränkung der Dateien, die indexiert werden sollen. Dieser wird mit Hilfe des glob Pattern beschrieben, siehe: What Is a Glob? . Beispiele:
|
VerzeichnisGegeben sei folgende Verzeichnisstruktur:
C:\data\1.pdf C:\data\1.doc C:\data\sub\1.xml C:\data\sub\2.pdf C:\data\sub\subsub\1.tiff
Wollen Sie z.B. alle XML Dateien im Wurzelverzeichnis und eine Ebene tiefer indexieren möchten, geben Sie folgende Werte an:
Titel: Verzeichnis 'data' Verzeichnis: C:\data Vezeichnistiefe: Direkt Dateitypen: *.xml
Wollen Sie hingegen alle PDF und Tiff Dateien indexieren, geben Sie folgende Werte an:
Titel: Verzeichnis 'data'
Verzeichnis: C:\data Vezeichnistiefe:
Alle Dateitypen: *.{pdf,tiff}
Indexierungs-Jobs zeitlich planen
Neben dem manuellen Starten von Jobs haben Sie die Möglichkeit, diese auch zu bestimmten Zeitpunkten wiederholt und automatisch durchführen zu lassen. Hierzu können Sie für jeden Job ein Scheduling explizit definieren. Aktivieren Sie hierzu die Option Scheduling beim Anlegen eines Jobs. Sie können ein Scheduling auch für einen Job nachträglich festlegen.
- Wann?
-
Eine vordefinierte Liste von Werten, die bestimmte Zeiträume abdecken. Diese sind:
-
Jede volle Stunde (d.h. stündlich)
-
Jeden Tag um 00:00 Uhr (d.h. täglich)
-
Jeden Sonntag um 00:00 Uhr (d.h. wöchentlich)
-
Jeden 1. Tag im Monat um 00:00 Uhr (d.h. monatlich)
-
- Cron Job
-
Hier werden das zeitliche Pattern in der Cron Notation eingetragen.
- Status
-
Hier wird festgelegt, ob das Scheduling aktiviert (scheduled) oder pausiert (inactive) werden soll.
Ist für einen Indexierungsjob eine Scheduling definiert, ergeben sich hieraus die folgenden Status:
scheduledDies ist der Normalzustand: der Job steht in der Warteschlange und es kontinuierlich überprüft, ob das durch den Scheduler angegeben Intervall erreicht wurde
pendingDas durch den Scheduler angegebene Intervall ist aktuell erreicht. Der Job wartet auf einen freien Platz in der Ausführungskette.
executingIndexierung des Jobs läuft. Nach erfolgreicher Indexierung wird wieder der Zustand scheduled für den Job gesetzt.
inactiveFür den Indexierungsjob ist ein Scheduling definiert, jedoch aktuell pausiert.
|
Die vordefinierten Notationen decken eine Vielzahl von Anwendungsfällen ab. Sollte Sie dennoch eine eigene Ablaufplanung des Jobs bevorzugen, können Sie die Einstellung auf Benutzerdefiniert setzen und einen eigenen Cron Job definiert. Die Erläuterung hierzu finden Sie dokumentiert im Quartz-Framework, welches Server-seitig verwendet wird: Quartz Cron Trigger Tutorial |
Löschen von Indexierungs-Jobs
Wählen Sie im Job-Manager mindestens einen Job mittels der Checkbox aus. Klicken Sie anschließend das Minus-Symbol oben links und bestätigen Sie den Löschvorgang.
| Durch das Löschen eines Jobs werden alle mit diesem Job verbundenen Dokumente aus dem Index gelöscht und stehen bei einer Suche nicht mehr zur Verfügung. |